Apprentissage non supervisé
Clustering, Réduction de dimension, détéction d'anomalie
1 Introduction
L’objectif de l’apprentissage non supervisé est d’extraire de la structure, des régularités ou des patterns à partir des seules données d’entrée, sans indication explicite de ce qu’il faut prédire.
Dans ce cadre, le modèle cherche à comprendre l’organisation interne des données : quelles observations se ressemblent, quelles dimensions sont redondantes, quels points sont atypiques, etc. Ces méthodes sont particulièrement utiles lorsque l’annotation des données est coûteuse, difficile, voire impossible, ce qui est fréquent dans des domaines comme la vision, la bio-informatique, la cybersécurité ou l’analyse de grands volumes de données.
Parmi les nombreuses tâches relevant de l’apprentissage non supervisé, nous nous interesserons dans ce cours à trois applications :
- La Réduction de dimension
- Le clustering
- La détection d’anomalies
Version slide du cours de 2024-2025 (plein de fautes et à moitié en anglais)
2 Réduction de dimension
Les données réelles sont souvent de grande dimension, ce qui complique leur visualisation, leur stockage et leur traitement, et peut dégrader les performances des modèles (phénomène de la “malédiction de la dimension”).
La réduction de dimension vise à projeter les données dans un espace de plus faible dimension tout en conservant l’information la plus pertinente possible. Elle est utilisée pour la visualisation, la compression, le débruitage ou comme étape de prétraitement avant d’autres algorithmes. Des méthodes classiques incluent l’ACP (PCA) et des approches non linéaires comme t-SNE ou UMAP.
2.1 PCA : Principal Composante Analysis
La PCA est une téchinique de reduction de dimensiosn linéaire, assimilable à une projection dans un espaces de dimensions plus faible ayant comme axes les vecteurs propres de la matrice de covariance de nos données. On peut décomposer la PCA en plusieurs étapes
Soit X ∈ ℝn×d la matrice de données, où chaque ligne représente un échantillon et chaque colonne une variable ou un descripteur. Chaque observation est donc un vecteur de dimension d, et l’ensemble du jeu de données peut être vu comme un nuage de points dans un espace de grande dimension.
Avant d’appliquer la PCA, les données sont standardisées. On commence par les centrer en soustrayant la moyenne de chaque variable, puis on les réduit souvent en divisant par l’écart-type. Le choix de réduire ou non le nuage de points est un choix de modèle. Si on ne réduit pas : une variable à forte variance va « tirer » tout l’effet de l’ACP à elle ; si l’on réduit : une variable qui n’est qu’un bruit va se retrouver avec une variance apparente égale à une variable informative. Si les variables aléatoires sont dans des unités différentes, la réduction est obligatoire.
À partir des données centrées Xc, on calcule la matrice de covariance Σ = (1/n) XcT Xc, qui mesure les corrélations entre toutes les paires de variables. Les coefficients diagonaux correspondent aux variances de chaque variable, tandis que les termes hors diagonale indiquent dans quelle mesure deux variables varient conjointement.
La PCA consiste ensuite à résoudre le problème aux valeurs propres Σv = λv. Les vecteurs propres définissent des directions orthogonales entre elles, appelées composantes principales, et les valeurs propres associées représentent la quantité de variance expliquée par chaque direction. En triant les valeurs propres par ordre décroissant, on obtient un classement des directions selon leur importance statistique.
On sélectionne alors les 3 à 5 plus grandes valeurs propres et leurs vecteurs propres associés pour construire la matrice de projection W. On peut aussi pour cela utiliser la méthode du coude qui consiste à tracer la variance expliquer par chacune des valeurs propres et de rechercher un point où la diminution devient moins significative. La projection des données Z = XcW fournit une représentation de plus faible dimension qui conserve un maximum de variance. Cette projection correspond également à la meilleure approximation linéaire de rang réduit des données au sens de l’erreur quadratique de reconstruction.
En pratique, c’est un méthode déja implementer dans , ``, très facile à utiliser.
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
n_components = 2
pca = PCA(n_components=n_components)
Exemple
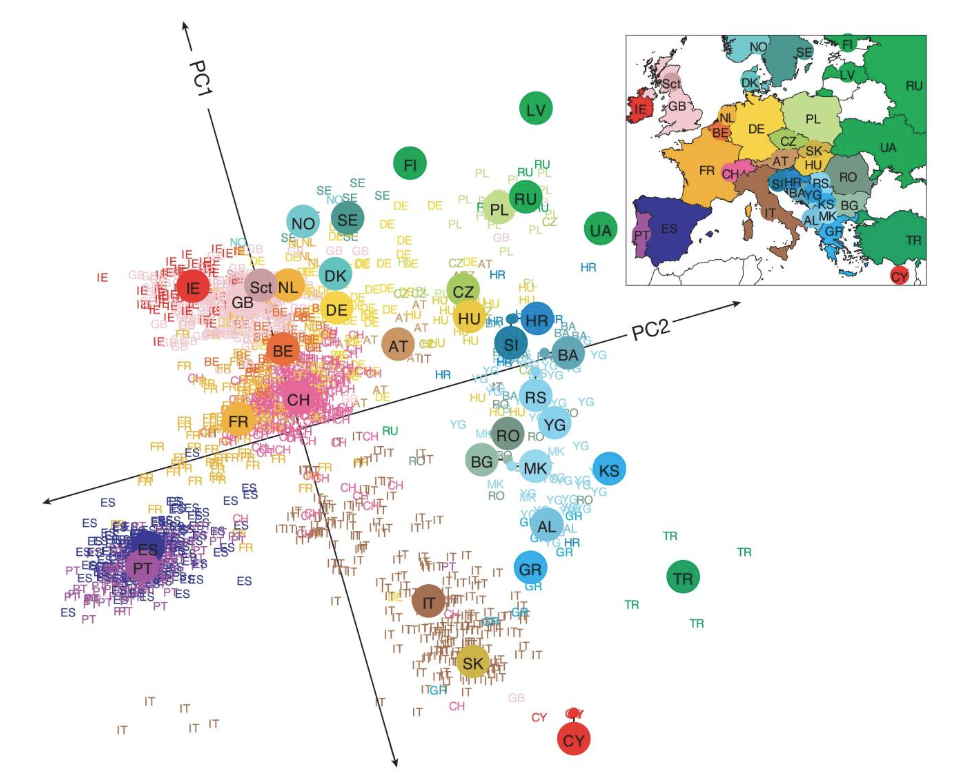
Voici un exemple de PCA tiré de l’article Novembre et al, Genes mirror geography within Europe, Nature, 2008. Les chercheurs ont sequencé les différence génétiques entre plus de 3000 personnes européenne à partir de leur ADN. Il ont ensuite fait une PCA sur leur données et fait remarquable, malgré de faibles niveaux moyens de différenciation génétique parmi les Européens, ils ont observer une correspondance étroite entre les distances génétiques et géographiques ; en effet, une carte géographique de l’Europe émerge naturellement comme un résumé bidimensionnel (PCA) de la variation génétique.
2.2 t-SNE : t-distributed Stochastic Neighbor Embedding
t-SNE (t-distributed Stochastic Neighbor Embedding) est une méthode de réduction de dimension non linéaire principalement utilisée pour la visualisation de données de grande dimension. Contrairement à la PCA, qui cherche à préserver la variance globale, t-SNE vise à conserver les relations de voisinage locales, c’est-à-dire que des points proches dans l’espace original doivent rester proches dans l’espace projeté.
La méthode commence par transformer les distances entre points dans l’espace original en probabilités de voisinage. Pour chaque paire de points, on définit une probabilité conditionnelle mesurant la similarité, basée sur une loi gaussienne centrée sur chaque point, avec une variance choisie de façon contrôler la taille effective du voisinage local.
Dans l’espace de faible dimension (généralement 2D ou 3D), t-SNE définit également des probabilités de similarité, mais cette fois à l’aide d’une loi de Student à une dimension (distribution à queue lourde). Ce choix permet de mieux séparer les groupes éloignés et de réduire le problème du « crowding », où trop de points seraient projetés au même endroit.
La projection est obtenue en minimisant la divergence de Kullback–Leibler entre la distribution de similarités dans l’espace original et celle dans l’espace projeté. Cette minimisation est réalisée par descente de gradient, ce qui rend l’algorithme itératif et potentiellement coûteux en temps de calcul pour de grands jeux de données.
En pratique, t-SNE produit souvent des visualisations avec des groupes bien séparés, ce qui en fait un outil très populaire pour l’exploration de données. Cependant, les distances globales et la taille relative des clusters ne sont pas nécessairement significatives, et les résultats peuvent dépendre fortement des hyperparamètres et de l’initialisation.
2.3 UMAP : Uniform Manifold Approximation and Projection
UMAP (Uniform Manifold Approximation and Projection) est, comme t-SNE, une méthode de réduction de dimension non linéaire destinée principalement à la visualisation de données de grande dimension. Elle repose toutefois sur une modélisation plus explicite de la structure de variété (manifold) des données, et cherche à préserver non seulement les voisinages locaux, mais aussi une partie de la structure globale.
Alors que t-SNE définit des similarités probabilistes entre toutes les paires de points, UMAP commence par construire un graphe des plus proches voisins, ce qui rend la méthode plus efficace en mémoire et en temps de calcul. Ce graphe représente la connectivité locale des données et sert de base à l’optimisation dans l’espace projeté.
Ensuite, dans l’espace de basse dimension, UMAP cherche une configuration de points dont le graphe de voisinage est le plus proche possible de celui de l’espace original. L’optimisation repose sur des forces d’attraction et de répulsion entre points connectés ou non connectés dans le graphe, et est résolue par descente de gradient stochastique.
Contrairement à t-SNE, où les distances entre clusters et leurs tailles relatives ne sont pas directement interprétables, UMAP tend à mieux conserver les relations globales entre groupes, ce qui permet parfois d’interpréter les distances inter-clusters de manière plus qualitative. De plus, UMAP permet plus naturellement la projection de nouvelles données dans l’espace appris, ce qui est plus délicat avec t-SNE.
En pratique, UMAP est largement utilisé pour la visualisation, la préanalyse et parfois comme étape de prétraitement avant du clustering ou de la classification. Comme pour t-SNE, les résultats dépendent des hyperparamètres, notamment le nombre de voisins et la distance minimale entre points projetés, qui contrôlent le compromis entre structure locale et globale.
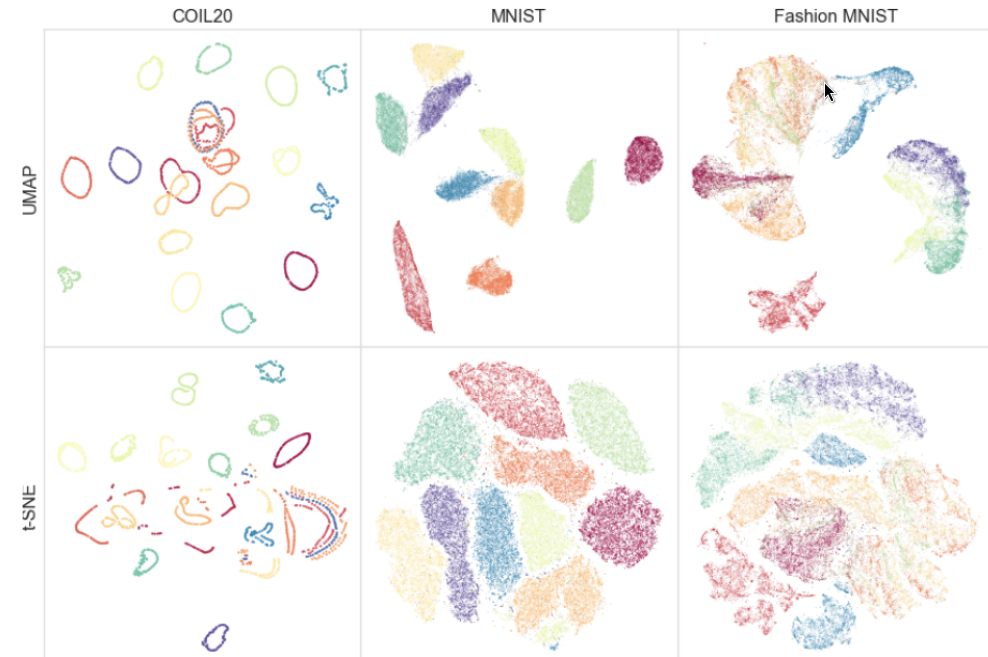
2.4 Différences visuelles entre T-SNE et UMAP
Comme dit plus haut, t-SNE vise à conserver les relations de voisinage locales alors que UMAP vise à conserver les relations globales entre groupes. Vous trouverez les représentation en dimension reduite de différents dataset “classique” de la computer vision calculer avec ces deux méthodes.
Remarque
3 Clustering
Le clustering consiste à regrouper automatiquement les données en groupes (clusters) tels que les points d’un même groupe soient similaires entre eux et différents de ceux des autres groupes. Il permet de découvrir des structures latentes dans les données, par exemple des segments de clients, des types de documents, ou des catégories d’images, sans connaître ces classes à l’avance.
3.1 K-Means
K-means est un algorithme de clustering qui vise à partitionner les données en k groupes,de sorte que les points d’un même cluster soient proches entre eux et éloignés de ceux des autres clusters. L’algorithme repose sur la minimisation de la variance intra-cluster, c’est-à-dire la somme des distances quadratiques entre chaque point et le centre (centroïde) de son cluster. Formellement, il cherche à minimiser la fonction objectif ∑i ||xi − μc(i)||², où μc(i) est le centroïde du cluster auquel appartient le point xi.
L’optimisation est réalisée de manière itérative par alternance entre deux étapes : (1) une étape d’affectation, où chaque point est assigné au cluster dont le centroïde est le plus proche, et (2) une étape de mise à jour, où chaque centroïde est recalculé comme la moyenne des points qui lui sont assignés. Ces deux étapes sont répétées jusqu’à convergence, c’est-à-dire jusqu’à ce que les affectations ne changent plus.
Contrairement à t-SNE et UMAP, qui sont principalement utilisés pour la visualisation, k-means est directement destiné à produire une segmentation exploitable des données. Il est cependant sensible à l’initialisation des centroïdes, peut converger vers des minima locaux, et suppose implicitement que les clusters sont de forme approximativement sphérique et de taille comparable.
En pratique, le choix du nombre de clusters k est un problème central, souvent abordé par des méthodes heuristiques comme la méthode du coude ou le score de silhouette. k-means est fréquemment combiné avec une réduction de dimension préalable (PCA ou UMAP) afin de réduire le bruit, accélérer les calculs et parfois améliorer la qualité du clustering.
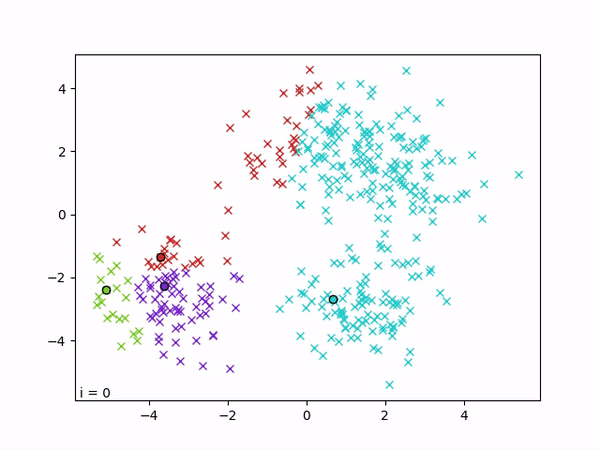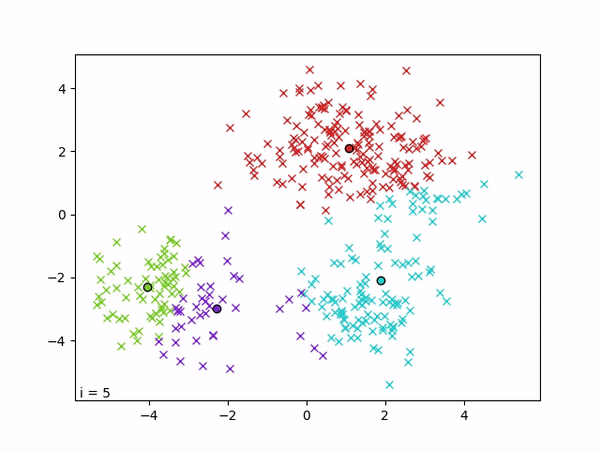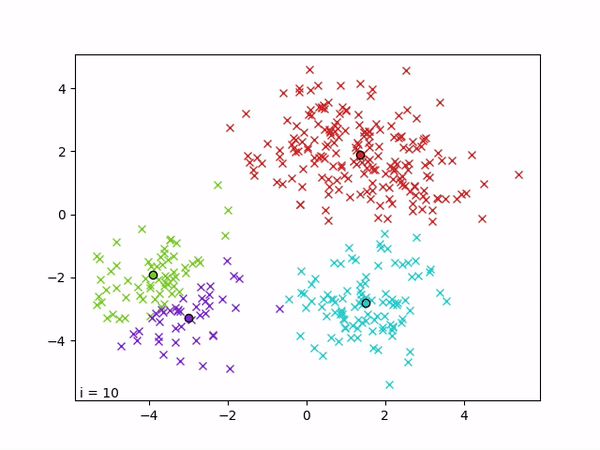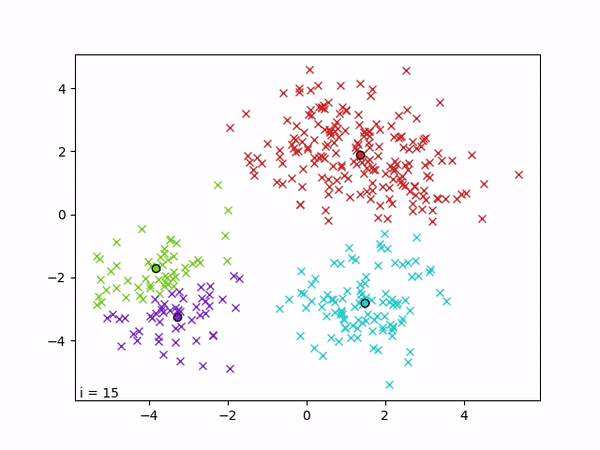
3.2 Mesure de la performance
Évaluer la qualité d’un clustering, et en particulier de k-means, est plus délicat que dans le cas supervisé, car il n’existe généralement pas de vérité terrain (labels) pour comparer directement les résultats. On utilise donc principalement des critères internes, basés uniquement sur les données et les clusters obtenus.
Un premier indicateur est l’inertie intra-cluster, qui correspond à la fonction objectif minimisée par k-means, c’est-à-dire la somme des distances quadratiques entre les points et leur centroïde. Une inertie faible indique des clusters compacts, mais elle décroît mécaniquement quand le nombre de clusters k augmente, ce qui rend difficile le choix optimal de k.
Pour aider à choisir k, comme pour les VP de la PCA, on utilise souvent la méthode du coude, qui consiste à tracer l’inertie en fonction de k et à rechercher un point où la diminution devient moins significative. Une autre mesure courante est le score de silhouette, qui compare pour chaque point sa similarité avec son propre cluster et avec les clusters voisins, et fournit un score compris entre −1 et 1, reflétant à la fois la compacité et la séparation des clusters.
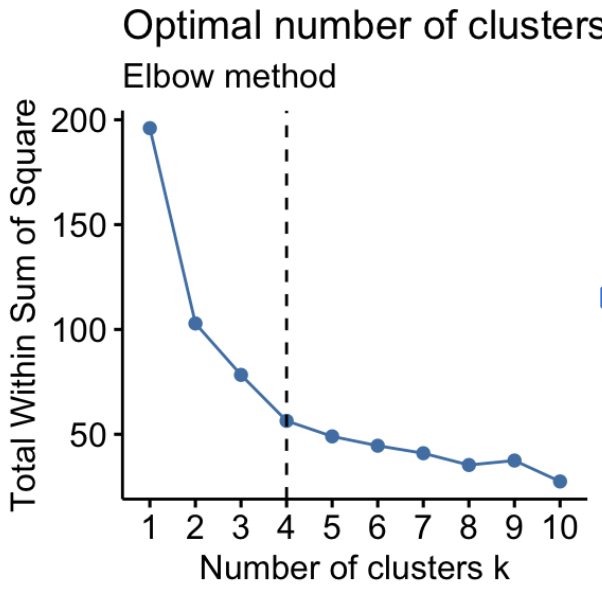
Lorsque des labels de référence sont disponibles (par exemple dans un cadre d’évaluation expérimentale), on peut utiliser des métriques externes comme l’Adjusted Rand Index (ARI) ou la Normalized Mutual Information (NMI), qui mesurent la similarité entre la partition obtenue et la partition réelle, indépendamment de l’ordre des labels.
3.3 Autres méthodes
Il existe de nombreuses méthodes de clustering, chacune reposant sur des présupposés différents concernant la forme, la densité ou la séparation des groupes dans les données. Certains algorithmes supposent que les clusters sont compacts et de forme simple, tandis que d’autres peuvent détecter des groupes de forme arbitraire ou de densité variable, et certains sont capables d’identifier explicitement du bruit ou des points atypiques.
Ces différences de modélisation impliquent que le choix d’un algorithme de clustering dépend fortement de la structure réelle des données, du niveau de bruit, de la dimension de l’espace et de la taille du jeu de données. Un algorithme performant dans un contexte donné peut produire des résultats très médiocres dans un autre, s’il viole ses hypothèses de base.
Le tableau comparatif ci-dessous résume les principales hypothèses, avantages et limites des méthodes de clustering les plus courantes, et permet de mieux comprendre dans quels contextes chacune d’entre elles est la plus adaptée.
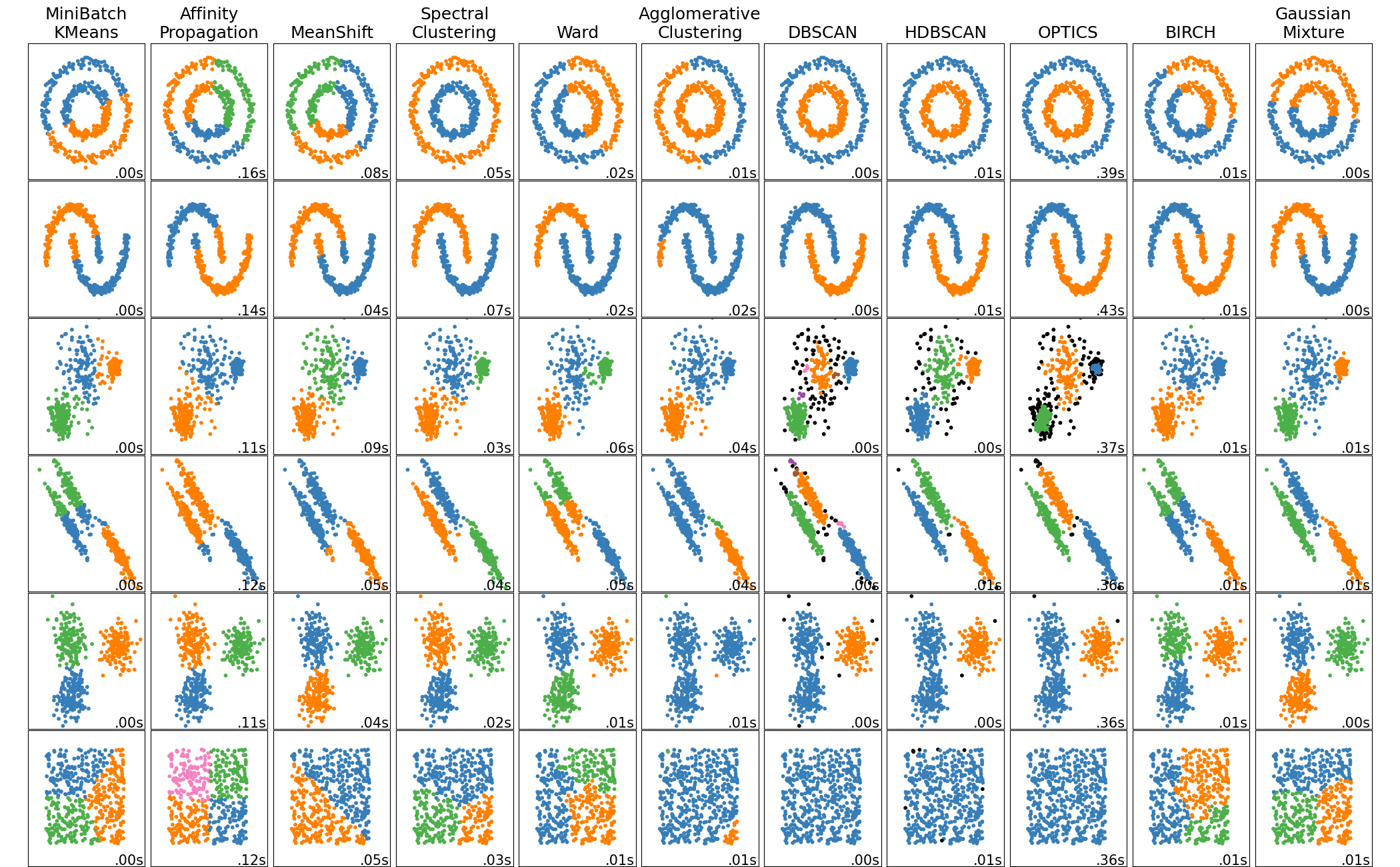
4 Détection d’anomalie
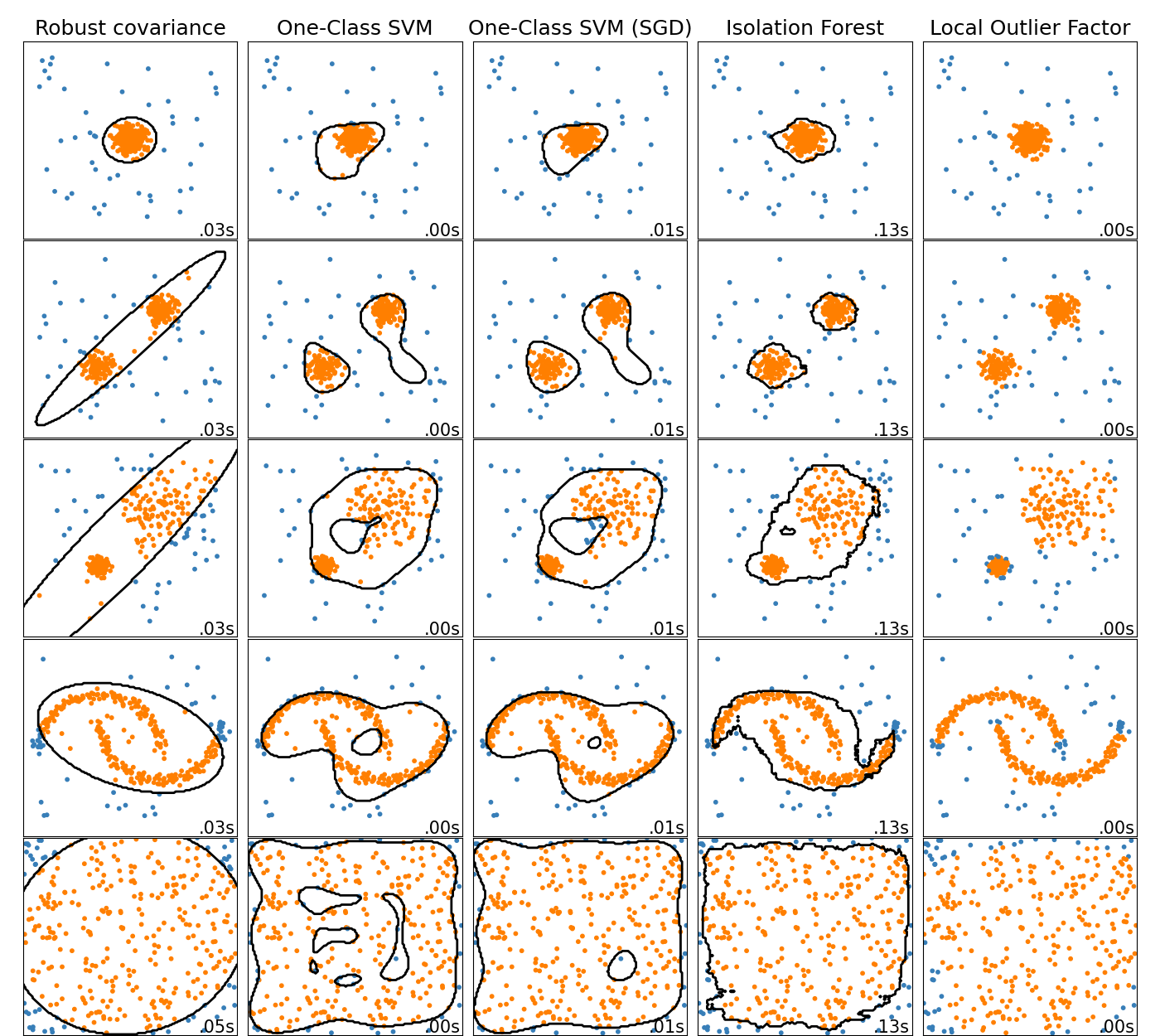
Cette tâche vise à identifier des observations rares ou atypiques par rapport au comportement général des données. Ces anomalies peuvent correspondre à des fraudes, des pannes, des intrusions ou des erreurs de mesure. L’idée est de modéliser ce qui est “normal” dans les données, puis de repérer ce qui s’en écarte significativement. Les méthodes incluent des approches statistiques, des modèles de densité ou des techniques basées sur l’isolement des points.
Il existe de nombreuses méthodes de détection d’anomalies, chacune reposant sur des hypothèses différentes concernant ce qui est considéré comme un comportement normal dans les données. Certaines approches modélisent explicitement la distribution des données normales, tandis que d’autres s’appuient sur des notions de densité, de distance ou d’isolement pour identifier des points atypiques.
Ces différences de modélisation impliquent que le choix d’une méthode dépend fortement de la structure des données, de la proportion d’anomalies, du niveau de bruit et du type d’anomalies recherchées (points isolés, sous-groupes rares, changements de régime, etc.). Une méthode efficace dans un contexte donné peut échouer si ses hypothèses ne correspondent pas aux caractéristiques réelles du problème.
Le tableau comparatif ci-dessous résume les principales hypothèses, avantages et limites des méthodes de détection d’anomalies les plus courantes, et permet de mieux comprendre dans quelles situations chacune d’entre elles est la plus pertinente.
5 Exercices
Dans le cas où vous ne souhaitez pas utiliser colab, vous pouvez télécharger les notebooks en cliquant sur le lien suivant : Correction_manip.zip