Partie 3 - Modélisation
1 Introduction
On réduit fréquemment le métier de data scientist à la conception et à l’entraînement de modèles sophistiqués d’intelligence artificielle, une perception largement nourrie par la médiatisation de systèmes spectaculaires comme ChatGPT. Cette vision est pourtant réductrice. En pratique, la construction de modèles ne représente qu’un segment du travail, au même titre que la production de graphiques ou de tableaux de bord. Dans de nombreuses structures où les rôles sont davantage spécialisés, ce sont même parfois les data engineers qui interviennent de manière centrale dans les étapes de préparation et de déploiement des modèles, voire dans la modélisation elle-même.
Les performances d’un modèle dépendent avant tout de la qualité des données qui lui sont fournies : collecte, nettoyage, mise en forme et structuration constituent des prérequis déterminants. Les approches fondées sur des architectures très complexes, capables de traiter des données peu organisées, exigent en contrepartie des moyens financiers et techniques considérables. De fait, seuls quelques acteurs disposent aujourd’hui des ressources nécessaires pour entraîner à partir de zéro des modèles de langage de grande taille, dont les coûts d’entraînement peuvent atteindre plusieurs centaines de milliers de dollars, avant même toute utilisation opérationnelle. À ces contraintes économiques s’ajoute un impact environnemental notable, les besoins en calcul se traduisant par une consommation énergétique élevée et, par conséquent, par une empreinte carbone significative.
Fort heureusement, la plupart des problèmes concrets peuvent être abordés à l’aide de méthodes bien plus frugales, qui seront au cœur des chapitres suivants. Cette partie du cours se concentre ainsi sur les algorithmes de machine learning entendus comme un ensemble de procédés permettant à un programme d’identifier des motifs, des tendances ou des relations statistiques à partir de données, sans que ces structures aient été explicitement codées à l’avance par des humains.
Cette partie est une introduction au machine learning. Le parti pris pédagogique consistant à privilégier, dans un premier temps, des méthodes élémentaires plutôt que de se tourner immédiatement vers des méthodes plus complexes comme les réseaux de neurones (vous aurez un cours dedier au prochain semestre sur ces méthodes) répond à plusieurs objectifs. Il s’agit avant tout d’introduire la logique scientifique qui sous-tend toute démarche d’apprentissage, en particulier la question cruciale de la capacité d’un modèle généraliser. C’est à dire, produire de bons résultats sur des nouvelles observations, et pas uniquement sur celles utilisées pour l’entraîner.
Par ailleurs, les méthodes issues du deep learning — et les réseaux de neurones en particulier — ne deviennent réellement avantageuses par rapport à des modèles plus sobres que dans des contextes bien spécifiques. Leur supériorité repose généralement soit sur la disponibilité de jeux de données extrêmement volumineux, comptant parfois plusieurs millions d’exemples, soit sur la présence de structures complexes difficiles à formaliser explicitement, comme celles que l’on rencontre dans le traitement du langage naturel ou de l’image. En dehors de ces situations, le recours à des techniques plus simples de machine learning s’avère le plus souvent amplement suffisant pour obtenir des performances satisfaisantes, sans supporter les coûts techniques et méthodologiques associés aux architectures profondes.
2 Un modèle c’est quoi ?
En machine learning, un modèle est principalement vu comme une fonction paramétrée capable de produire des prédictions à partir d’entrées, dont les paramètres sont ajustés automatiquement à partir de données. L’objectif est de capturer des relations, des régularités ou des structures sous-jacentes afin de généraliser à de nouvelles observations. Le modèle est défini par une famille de fonctions paramétrées (par exemple une droite en régression linéaire, ou un réseau de neurones profond) et un algorithme d’apprentissage qui ajuste ces paramètres en optimisant une fonction de coût ou un critère statistique.
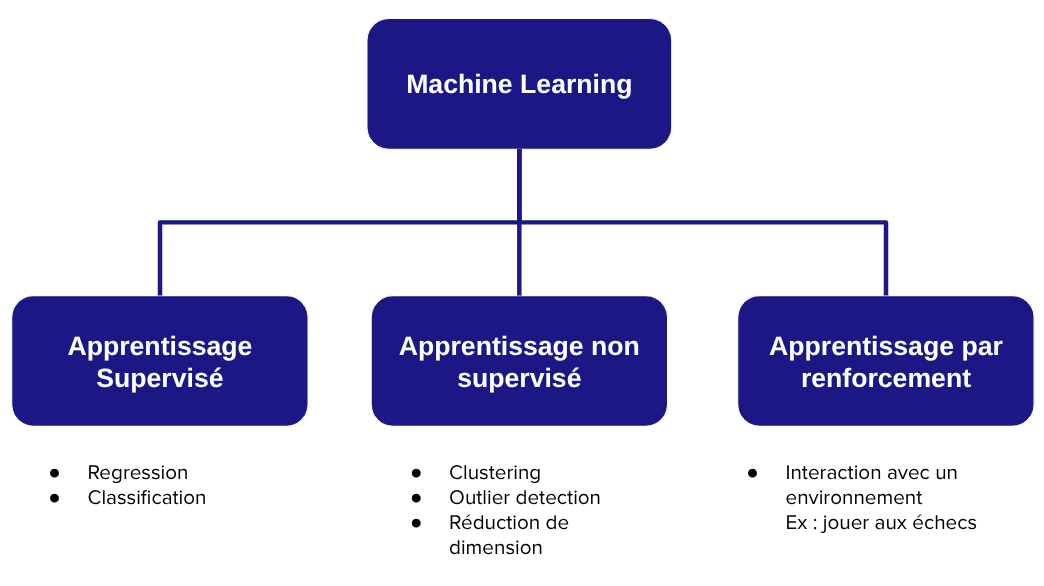
Selon la nature des données disponibles, on distingue plusieurs cadres d’apprentissage :
- L’apprentissage supervisé, le modèle apprend à partir de paires (entrée, sortie) labelisé, avec des objectifs de régression ou de classification.
- L’apprentissage non supervisé, où aucun label n’est fournie : le modèle cherche alors à révéler la structure intrinsèque des données, par exemple le clustering (k-means, DBSCAN) pour identifier des groupes homogènes, ou la réduction de dimension (ACP/PCA, autoencodeurs) pour projeter les données dans un espace latent plus compact tout en conservant l’information essentielle.
Note
D’un point de vue plus pratique, vous trouverez ci-dessous une cheat-sheet, qui résume sous forme d’un arbre de décision quels modèles utiliser en fonction du contexte.
