Apprentissage supervisé
Régression et classification.
1 Introduction
L’apprentissage supervisé est l’un des principaux paradigmes du machine learning. Il consiste à apprendre une fonction à partir d’exemples labélisé, c’est-à-dire d’un ensemble de données pour lesquelles on connaît à la fois les entrées (ou variables explicatives, appelées features) et les sorties attendues (appelées labels ou cibles). L’objectif est de construire un modèle capable de généraliser, c’est-à-dire de produire des prédictions correctes sur de nouvelles données jamais vues auparavant.
On peut utiliser l’apprentissage supervisé pour résoudre un très large éventail de problème. Voici quelques exemples non exaustif d’application :
- Prédiction des prix d’actions au cours du temps
- Ciblage publicitaire à partir des données utilisateur
- Estimer le redshift d’une galaxie
- Prédire si un paiement par carte est frauduleux
Cependant, on peut classer ces problèmes en deux grandes catégories : la régression et la classification.
-
En régression, la variable cible est continue. Le but est de prédire une valeur numérique, par exemple le prix d’un logement, la consommation énergétique d’un bâtiment ou la température future. Les modèles cherchent alors à approximer une relation fonctionnelle entre les variables d’entrée et une sortie réelle.
-
En classification, la variable cible est discrète et correspond à une ou plusieurs catégories. Il s’agit par exemple de déterminer si un email est un spam ou non, de reconnaître un chiffre manuscrit, ou d’identifier la classe d’un objet dans une image. Le modèle apprend à séparer l’espace des données en régions correspondant aux différentes classes.
Version slide du cours de 2024-2025 (plein de fautes et à moitié en anglais)
2 Formalisme
Le formalisme de l’apprentissage supervisé consiste à estimer une fonction inconnue reliant les variables d’entrée mesurables X ∈ ℝd à une sortie cible y, que l’on note y = f(X). On dispose d’un ensemble d’apprentissage composé de N exemples (xi, yi), et l’objectif est d’estimer une fonction f̂ qui minimise une erreur moyenne du type ∑i=1N ℓ( f(xi), yi ). Dans de nombreuses situations, les variables X sont facilement mesurables, alors que la variable y est soit impossible à observer, soit trop coûteuse ou complexe à mesurer expérimentalement ; le modèle sert alors d’approximation de la relation physique, biologique ou économique sous-jacente.
- Lorsque la variable cible est continue, y ∈ ℝ, on parle de régression, par exemple pour prédire un prix, un redshift ou un taux métabolique, et on minimise typiquement une erreur quadratique.
- Lorsque la variable cible est discrète, y ∈ {1,…,K}, on parle de classification, par exemple pour détecter une cellule cancereuse à partir d’une image biomedical ou distinguer des images de chien et de chat ; le modèle apprend alors une frontière de décision qui partitionne l’espace des caractéristiques en régions associées aux différentes classes.
3 Optimisation
3.1 Descente de gradient
En apprentissage supervisé, on dispose de données sous forme de paires (xi, yi), où xi ∈ ℝd représente les entrées et yi la sortie cible. On choisit un modèle paramétrique noté f(x, w), par exemple un modèle linéaire y = f(x, w) = w0 + x · w1, où w = (w0, w1) sont les paramètres à apprendre. On définit ensuite une fonction de perte (Loss function) L(w) qui mesure l’erreur de prédiction sur l’ensemble des données..
L’objectif de l’apprentissage est alors de résoudre le problème d’optimisation argminw L(w), c’est-à-dire de trouver les valeurs de w qui minimisent la Loss function.
Dans la majorité des modèles réalistes, la fonction L(w) n’admet pas de solution analytique avec une forme close, et l’on utilise donc des méthodes de descente de gradient, qui mettent à jour les paramètres selon la règle w ← w − η ∇w L(w), où η est le taux d’apprentissage.
On peut interpréter la Loss comme une surface de hauteur L définie sur l’espace des paramètres, par exemple avec w0 en latitude, w1 en longitude, et L(w) en altitude : l’algorithme cherche à descendre vers les points les plus bas de cette surface. Cependant, cette surface peut contenir plusieurs minima locaux, dans lesquels l’algorithme peut se bloquer sans atteindre le minimum global, ce qui rend l’initialisation des paramètres et le choix de l’algorithme d’optimisation particulièrement importants.
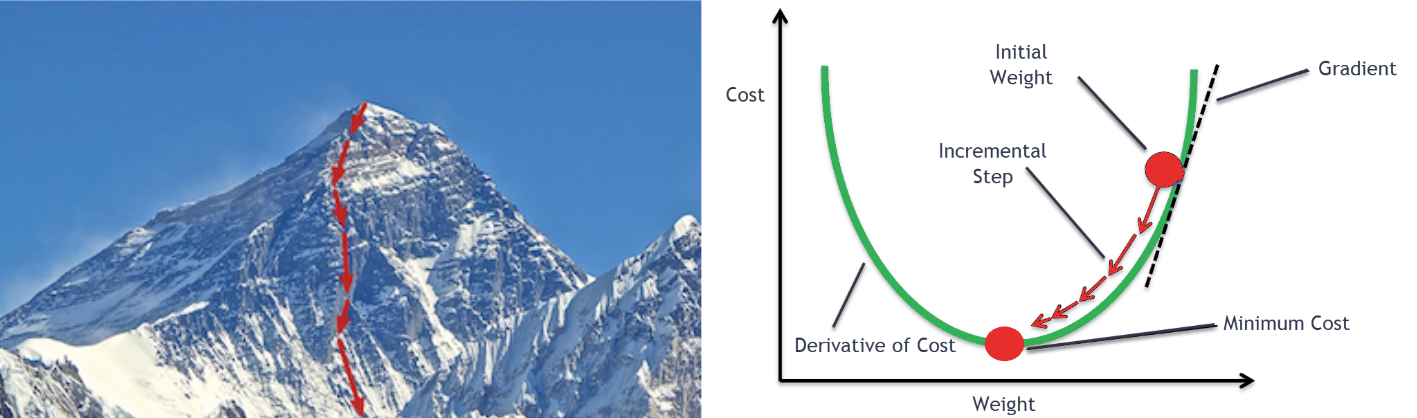
3.2 Quelques exemples de Loss function
En régression, où la variable cible est continue, plusieurs fonctions de perte sont couramment utilisées.
- La plus classique est la Mean Squared Error (MSE), définie par L = (1/N) ∑i ( yi − f(xi) )², qui pénalise fortement les grandes erreurs mais est sensible aux valeurs aberrantes.
- Une alternative plus robuste est la Mean Absolute Error (MAE), donnée par L = (1/N) ∑i | yi − f(xi) |, qui réduit l’influence des outliers mais conduit à une fonction de coût moins lisse.
- Un compromis entre les deux est la log-cosh loss, définie par L = (1/N) ∑i log( cosh( yi − f(xi) ) ), qui se comporte comme la MAE lorsque l’erreur est grande (croissance quasi linéaire) et comme la MSE lorsque l’erreur est faible (comportement quadratique).
En classification binaire, la variable cible prend des valeurs y ∈ {0, 1}, et le modèle produit une probabilité de prédiction p = P(y = 1 | x). La fonction de perte standard est l’entropie croisée binaire, définie par L = − (1/N) ∑i [ yi log(pi) + (1 − yi) log(1 − pi) ], qui pénalise fortement les prédictions très confiantes mais incorrectes.
En classification multiclasse, on considère K classes et une variable cible codée en “one-hot”, avec yi,c = 1 si l’échantillon i appartient à la classe c, et 0 sinon. Le modèle prédit une distribution de probabilités pi,c = P(y = c | xi), vérifiant la contrainte ∑c=1K pi,c = 1 pour chaque échantillon. La perte utilisée est l’entropie croisée catégorielle : L = − (1/N) ∑i ∑c=1K yi,c log(pi,c), qui mesure la divergence entre la distribution prédite par le modèle et la distribution vraie des classes.
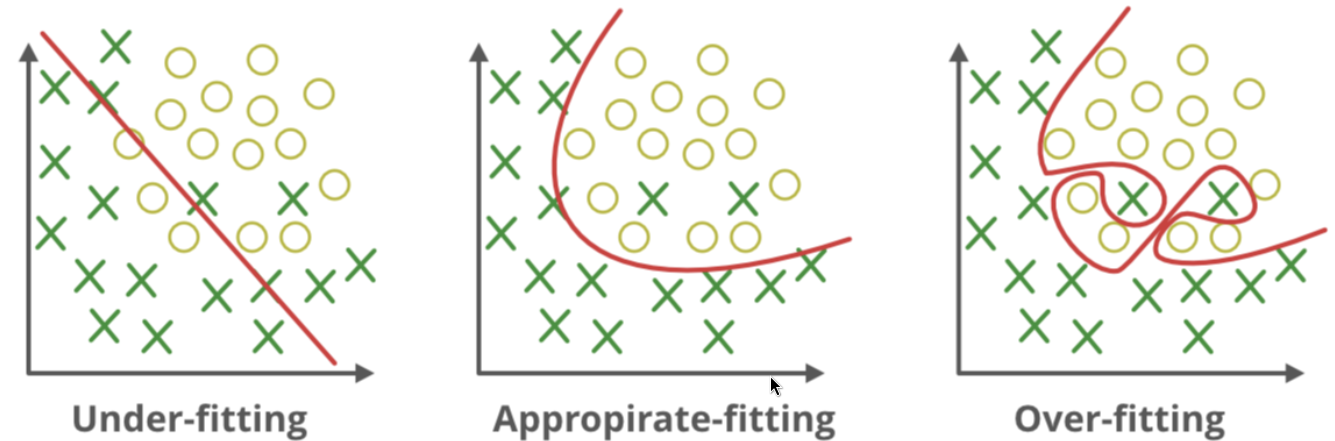
3.3 Overfitting/underfitting
On distingue deux problèmes classiques : le sur-apprentissage (overfitting) et le sous-apprentissage (underfitting). On peut les comprendre avec une analogie scolaire : le jeu d’entraînement (train dataset) correspond aux devoirs, tandis que le jeu de test (test dataset) correspond à l’examen.
Un modèle en overfitting obtient une très faible erreur sur les devoirs mais échoue à l’examen : il a essentiellement appris par cœur les exercices du cours sans comprendre les concepts généraux, ce qui se traduit par une mauvaise généralisation. À l’inverse, un modèle en underfitting n’arrive pas non plus à résoudre correctement les devoirs, car il est trop simple pour capturer la structure des données ; il échoue donc à la fois sur l’entraînement et sur le test.
L’objectif est de trouver un compromis entre ces deux extrêmes en apprenant un modèle qui capture les régularités utiles sans mémoriser le bruit, ce qui revient à minimiser l’erreur de généralisation.
4 Evaluation
Pour être sur de ne pas tombé dans le sur-apprentissage ou le sous-apprentissage, la démarche générale en machine learning est la suivante :
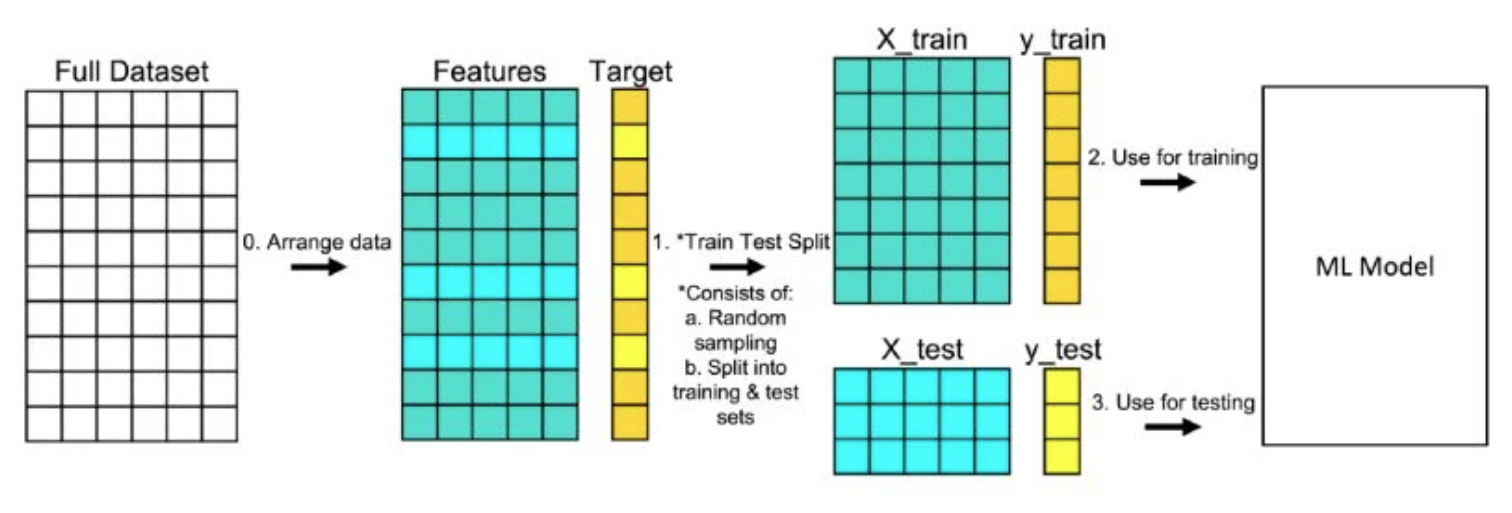
On découpe l’ensemble des données disponibles en deux parties, un échantillons d’apprentissage et un de test. Il existe d’autre moyen de partitionner et valider un dataset, notamment la partition train/val/test et la cross-validation que vous aborderer durant le cours de réseaux de neuronnes au prochain semestre.
En apprentissage automatique, on entraîne les modèles en minimisant une fonction de perte (loss function) L, qui est choisie pour être optimisable (différentiable, stable numériquement), mais qui n’a pas toujours un sens direct pour le problème réel. Par exemple, on minimise une entropie croisée ou une erreur quadratique, alors que l’objectif final peut être médical, économique ou sociétal. C’est pourquoi on utilise en plus une ou plusieurs métriques d’évaluation pour juger la qualité du modèle, qui peuvent parfois être identiques à la loss, mais le plus souvent sont différentes. Une bonne métrique doit être informative, justifiée par le contexte applicatif, facilement compréhensible si possible, et surtout vérifier que meilleur modèle ⇒ meilleur score.
Considérons par exemple la base MNIST (chiffres de 0 à 9). Si l’on construit un modèle binaire qui prédit si une image est un 0 ou non, une métrique naturelle est l’accuracy, définie par Acc = (TP + TN) / (TP + TN + FP + FN). Un score de 90% peut sembler bon, mais cela dépend fortement de la distribution des classes et du niveau de difficulté du problème : si seulement 10% des images sont des zéros, un classifieur trivial qui prédit toujours “non-0” obtient déjà 90% d’accuracy sans rien apprendre.
Cette limite est encore plus critique dans des applications sensibles comme le pré-dépistage du cancer, où l’on prédit la présence de la maladie à partir d’un test sanguin. Un modèle avec 99% d’accuracy peut être trompeur si la maladie est rare : il peut prédire presque toujours “pas de maladie” et rester très précis tout en ratant la majorité des cas positifs. Dans ce contexte, des métriques comme :
- la précision Precision = TP / (TP + FP)
- le rappel (sensibilité) Recall = TP / (TP + FN) sont souvent plus pertinentes.
Par exemple, une précision de 50% signifie qu’un patient sur deux déclaré positif est en réalité sain, ce qui peut être inacceptable selon le contexte clinique, même si l’accuracy globale reste élevée.
Ainsi, le choix des métriques est indissociable des enjeux du problème, et l’évaluation doit toujours être interprétée à la lumière de l’application finale.
4.1 Métriques pour la classification
Classification Binaire (0-1, negative-positive)
- TP: true positive
- FP: false positive
- TN: true negative
- FN: false negative
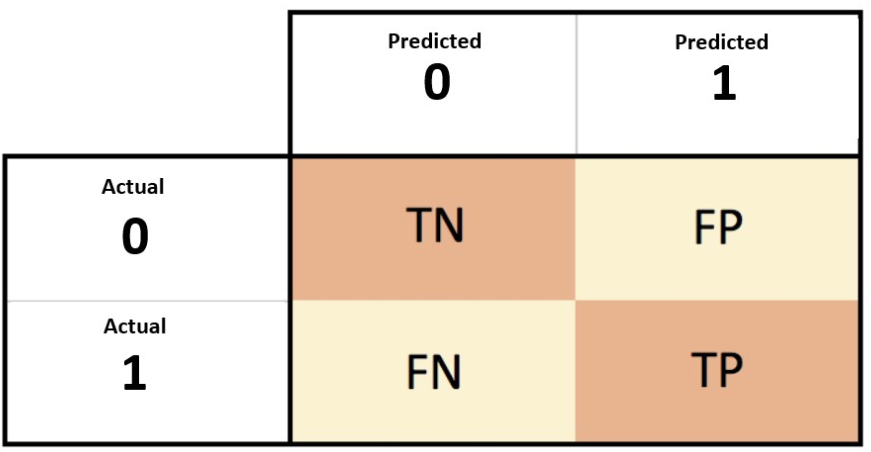
Voici quelques métrique à utile dans ce cas :
- Accuracy = (TP + TN) / (TP + TN + FP + FN)
- true positive rate (ou recall/sentivity), TPR = (TP) / (TP + FN)
- true negative rate (ou specificity), TNR = (TP) / (TP + FN)
- false positive rate: 1 - TNR
- F1 score, précision …
La fonction classification_report de sk-learn vous fournie directement l’ensemble de ces métriques.
4.2 Métriques pour la régression
En régression, plusieurs métriques permettent d’évaluer la qualité d’un modèle en comparant les valeurs réelles yi et les prédictions ŷi, elles peuvent aussi être utiliser comme loss function (si différentiable) :
- MSE (Mean Squared Error) = (1/N) ∑i=1N ( yi − ŷi )². Elle mesure l’erreur quadratique moyenne et pénalise fortement les grandes erreurs.
-
MAE (Mean Absolute Error) = (1/N) ∑i=1N | yi − ŷi |. Elle correspond à l’erreur absolue moyenne et est plus robuste aux valeurs aberrantes que la MSE.
-
RMSE (Root Mean Squared Error) = √( (1/N) ∑i=1N ( yi − ŷi )² ). C’est la racine carrée du MSE.
- Coefficient de détermination R² = 1 − [ ∑i ( yi − ŷi )² / ∑i ( yi − ȳ )² ], où ȳ est la moyenne des valeurs réelles. Il mesure la proportion de la variance expliquée par le modèle : R² = 1 correspond à une prédiction parfaite, R² = 0 à un modèle équivalent à la moyenne, et des valeurs négatives indiquent un modèle pire que cette baseline.
5 Exercices
Dans le cas où vous ne souhaitez pas utiliser colab, vous pouvez télécharger les notebooks en cliquant sur le lien suivant : Correction_manip.zip