Introduction à Pandas
1 Introduction
Depuis une dizaine d’années, le package Pandas s’impose comme l’une des composantes essentielles de l’écosystème de la data science. Avant son apparition, le DataFrame, structure centrale dans des langages comme R ou Stata, manquait cruellement à l’univers Python. Pourtant, grâce à NumPy, les fondations nécessaires existaient déjà — il ne manquait qu’une réorganisation adaptée aux besoins des data scientists.
C’est Wes McKinney qui a comblé ce manque en développant Pandas, une bibliothèque offrant un DataFrame reposant sur NumPy. Ce projet a marqué un tournant majeur pour l’analyse de données en Python et explique aujourd’hui la place dominante de Pandas dans l’écosystème de la data science.
Dans ce chapitre, nous aborderons les aspects les plus essentiels de Pandas pour une initiation à la data science, tout en invitant les lecteurs souhaitant aller plus loin à explorer les nombreuses ressources disponibles sur le sujet, notamment l’ouvrage de Wes McKinney.
Comme la valeur des données réside souvent dans leur croisement — par exemple, relier un enregistrement à des informations contextuelles ou fusionner deux bases clients pour obtenir une vision plus complète —, le chapitre suivant expliquera aussi comment associer plusieurs jeux de données avec Pandas.
1.1 Données
Les données choisies pour illustrer ce tutoriel sont issues d’une compétition du site Kaggle: Titanic: Machine learnic from Disaster. Le concours est terminé mais les données sont toujours disponibles sur le site avec des tutoriels utilisant Excel, Python ou R.
1.2 Environment
Nous suivrons les conventions habituelles dans l’import des packages :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Pour obtenir des résultats reproductibles, on peut fixer la racine du générateur pseudo-aléatoire.
np.random.seed(42)
2 Pandas et sa logique
2.1 Le Dataframe Pandas
L’élément central de la logique de Pandas est le DataFrame. Il s’agit d’une structure de données bidimensionnelle, organisée en lignes et colonnes. Contrairement à une matrice, les colonnes d’un DataFrame peuvent contenir des types de données différents, offrant ainsi une grande flexibilité pour la manipulation et l’analyse des données.
On se repère dans un DataFrame à l’aide des éléments suivant :
- l’indice de la ligne;
- le nom de la colonne;
- la valeur de la donnée.
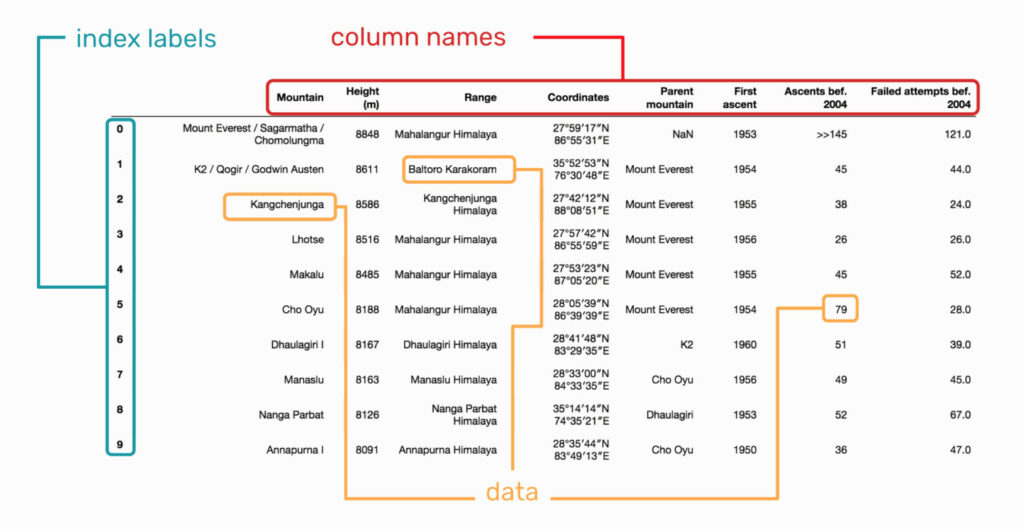
Dans la pratique, il s’agit d’un tableau bi-dimensionnel avec des index de lignes et de colonnes mais il peut également être vu comme une liste de Series partageant le même index. L’index de colonne (noms des variables) est un objet de type dict (dictionnaire). C’est la classe qui sera principalement utilisée dans ce tutoriel.
2.2 La Serie Pandas
Le DataFrame que l’on a vu juste avant est en réalité une collection d’un objet appelées pandas.Series. Ces Series sont des objets unidimensionnels, qui constituent une extension des arrays unidimensionnels de NumPy.
Pour faciliter le traitement des données catégorielles ou temporelles, Pandas propose des types de variables supplémentaires par rapport à NumPy, tels que categorical, datetime64 et timedelta64. Ces types spécifiques sont associés à des méthodes optimisées, permettant une manipulation plus efficace et intuitive de ce genre de données.
Par ailleurs, une pandas.Series peut adopter plusieurs types de données, en extension de ceux disponibles nativement en Python. Le type d’une variable détermine son comportement et les opérations possibles : en effet, une opération peut avoir un sens pour une valeur numérique, mais pas nécessairement pour une valeur textuelle ou catégorielle.
2.3 Principe de tidy Data
Le concept de tidy data, popularisé par Hadley Wickham via ses packages R (voir rajouter article wickham), est parfaitement pertinent pour décrire la structure d’un DataFrame Pandas. Les trois règles des données tidy sont les suivantes :
- Chaque variable possède sa propre colonne ;
- Chaque observation possède sa propre ligne ;
- Une valeur, matérialisant une observation d’une variable, se trouve sur une unique cellule.

Ces principes peuvent vous apparaître de bon sens mais vous découvrirez que de nombreux formats de données ne correspondent pas à ce principe. Par exemple, des tableurs Excel proposent régulièrement des valeurs à cheval sur plusieurs colonnes ou plusieurs lignes fusionnées. Restructurer cette donnée selon le principe des tidy data sera un enjeu pour être en mesure d’effectuer des traitements sur celle-ci.
3 Création et manipulation de base d’un Dataframe
3.1 Création
La création d’un DataFrame peut se faire de différentes manières. La méthode la plus courante consiste à partir d’un dictionnaire de listes, où chaque clé représente le nom d’une colonne et chaque liste associée contient les valeurs correspondantes.
data = {"state": ["Ohio", "Ohio", "Ohio",
"Nevada", "Nevada"],
"year": [2000, 2001, 2002, 2001, 2002],
"pop": [1.5, 1.7, 3.6, 2.4, 2.9]}
dataframe = pd.DataFrame(data)
dataframe
| state | year | pop | |
|---|---|---|---|
| 0 | Ohio | 2000 | 1.5 |
| 1 | Ohio | 2001 | 1.7 |
| 2 | Ohio | 2002 | 3.6 |
| 3 | Nevada | 2001 | 2.4 |
| 4 | Nevada | 2002 | 2.9 |
3.2 Indexation
La différence essentielle entre une Series et un objet Numpy est l’indexation. Dans un Numpy array, les éléments sont accessibles uniquement par leur position (entier). Dans une Series ou un DataFrame, chaque élément est accessible via un indice de position mais aussi via un index, souvent plus explicite.
Ceci permet d’accéder à la donnée de manière plus naturelle, en utilisant les noms de colonne par exemple:
dataframe["state"]
0 Ohio 1 Ohio 2 Ohio 3 Nevada 4 Nevada Name: state, dtype: object
La présence d’indices rend le subsetting — c’est-à-dire la sélection de lignes ou de colonnes — particulièrement simple. Les DataFrames disposent en effet de deux types d’indices : ceux des lignes et ceux des colonnes. Il est donc possible d’effectuer des sélections selon ces deux dimensions. Comme on le verra dans les exercices suivants, cette structure facilite grandement la sélection de lignes.
dataframe.loc[dataframe["state"] == "Ohio"]
| state | year | pop | |
|---|---|---|---|
| 0 | Ohio | 2000 | 1.5 |
| 1 | Ohio | 2001 | 1.7 |
| 2 | Ohio | 2002 | 3.6 |
On peut voir sur la gauche l’affichage du numéro de la ligne, il s’agit ici de l’indice par défaut pour la dimension des lignes, puisque nous n’en avons pas défini un nous-mêmes. Bien que la définition d’un indice ne soit pas obligatoire, il est tout à fait possible d’en utiliser un correspondant à une variable d’intérêt (nous verrons cela plus en détail lors de l’étude de groupby dans le prochain chapitre). Cependant, cette approche peut s’avérer trompeuse ; il est donc conseillé de ne l’utiliser que de manière temporaire et de procéder régulièrement à un reset_index() pour revenir à une structure plus claire.
4 Lecture et écriture des données
S’il fallait créer à la main tous ses DataFrames à partir de vecteurs ou de dictionnaire, Pandas ne serait pas pratique. Pandas propose de nombreuses fonctions pour lire des données stockées dans des formats différents (csv, texte, fixe, compressé, xml, html, hdf5, …). Dans ce cours, nous allons nous contenté de décrire les fonctions les plus utiles read_csv et read_table pour lire des fichiers textes et générer un objet de classe ` DataFrame`.
💡Remarque
engine=Python). 4.1 Exemple pratique : Titanic
Comme dit plus haut, les données utilisées dans ce tutoriel proviennent de Titanic: Machine learnic from Disaster. Le Titanic est l’un des paquebots les plus célèbres de l’histoire. Lors de son voyage inaugural en avril 1912, il a heurté un iceberg et a coulé dans l’Atlantique Nord, entraînant la mort de nombreux passagers et membres d’équipage.
Une des raisons du drame, qui provoqua la mort de 1502 personnes sur les 2224 passagers et membres d’équipage, fut le manque de canots de sauvetage. Il apparaît que les chances de survie dépendaient de différents facteurs (sexe, âge, classe…). Le but du concours était de construire un modèle de prévision (classification supervisée) de survie en fonction de ces facteurs. Les données sont composées d’un échantillon d’apprentissage (891) et d’un échantillon test (418) chacun décrit par 11 variables dont la première indiquant la survie ou non lors du naufrage.
5 Exploration d’un DataFrame
Pandas adopte une structure de données familière pour les utilisateurs de logiciels statistiques tels que R en s’inspirant lui aussi fortement de la logique SQL. La philosophie reste similaire : on réalise des opérations de sélection de lignes ou de colonnes, des tris basés sur les valeurs de certaines variables, ainsi que des traitements standardisés sur ces variables. De manière générale, Pandas encourage l’utilisation des noms de variables plutôt que des indices de lignes ou de colonnes, afin de rendre les manipulations plus explicites et cohérentes.
Pandas offre un très large éventail de fonctionnalités déjà intégrées. Avant de coder une fonction manuellement, il est donc fortement conseillé de vérifier si une implémentation native n’existe pas déjà dans NumPy, Pandas ou une autre bibliothèque. Dans la majorité des cas, il est préférable d’utiliser ces solutions existantes, car elles sont plus optimisées et performantes que celles développées manuellement.
df = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
df
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 12 columns
💡Remarque
df.head() et df.tail() pour afficher respectivement les premières et dernières lignes du DataFrame. 5.1 Dimensions et structure des données
La première étape dans l’exploration d’un DataFrame consiste à examiner certains de ses attributs et ses dimensions. Les attributs axes, columns et index permettent d’accéder aux informations relatives aux lignes et aux colonnes du DataFrame. Les attributs ndim, shape et size fournissent des informations sur la structure globale du DataFrame, telles que le nombre de dimensions, la forme (nombre de lignes et de colonnes) et la taille totale (nombre d’éléments).
df.axes
[RangeIndex(start=0, stop=891, step=1),
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')] df.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object') df.index
RangeIndex(start=0, stop=891, step=1)
df.ndim
2
df.shape
(891, 12)
df.size
10692
Pour déterminer le nombre de valeurs uniques d’une variable, on utilise la méthode nunique. Par exemple, pour la variable Pclass :
df['Pclass'].nunique()
3
5.2 Accéder au colonnes d’un DataFrame
Avec Pandas, pour accéder à une colonne dans son ensemble on peut utiliser la syntaxe suivante :
-
dataframe['variable']pour renvoyer la variable sous forme de Series. -
dataframe.loc[:,['variable']]pour renvoyer la variable sous forme de DataFrame.
Pour accéder à plusieurs colonnes, on utilise la syntaxe suivante :
-
dataframe[['variable1', 'variable2']] -
dataframe.loc[:,['variable1', 'variable2']]
C’est equivalent à SELECT variable1, variable2 FROM dataframe en SQL.
5.3 Accéder aux lignes d’un DataFrame
Pour accéder aux lignes d’un DataFrame, on utilise principalement deux méthodes : df.loc et df.iloc.
-
df.ilocpermet de sélectionner des lignes en utisant les indices. Il faut faire attention car les indices peuvent être modifiés au cours de la manipulation des données. -
df.locutilise des labels.
iloc va se référer à l’indexation de 0 à N (avec N égal df.shape[0]). De son côté, loc va se référer aux valeurs de l’index de df.
df_example = pd.DataFrame(
{'month': [1, 4, 7, 10], 'year': [2012, 2014, 2013, 2014], 'sale': [55, 40, 84, 31]})
df_example = df_example.set_index('month')
df_example
| year | sale | |
|---|---|---|
| month | ||
| 1 | 2012 | 55 |
| 4 | 2014 | 40 |
| 7 | 2013 | 84 |
| 10 | 2014 | 31 |
-
df_example.loc[1, :]donnera la première ligne dedf(ligne où l’indicemonthest égal à 1) -
df_example.iloc[1, :]donnera la deuxième ligne (car l’indexation en Python commence à 0) -
df_example.iloc[:, 1]donnera la deuxième colonne -
df_example.iloc[1, 1]donnera le deuxième éléments de la deuxième colonne
6 Les principales manipulation de données
Les opérations les plus courantes en SQL sont synthétisées dans le tableau ci-dessous. Il est utile de les connaître, car de nombreuses syntaxes de manipulation de données s’en inspirent. D’une manière ou d’une autre, ces opérations couvrent l’essentiel des usages liés au traitement et à la transformation des données.
| Opération | SQL | Pandas |
|---|---|---|
| Sélectionner des variables par leur noms | SELECT | df[['var1','var2']] |
| Sélectionner des observations selon une condition | FILTER | df.loc[df['var1'] > 10] |
| Trier les observations selon une ou plusieurs variables | SORT BY | df.sort_values(by=['var1','var2'], ascending=[True, False]) |
| Ajouter des variables qui sont fonction d’autres variables | SELECT *, LOG(var1) AS new_var FROM df | df['new_var'] = np.log(df['var1']) |
| Effectuer une opération par groupe | GROUP BY | df.groupby('var1').mean() |
| Joindre deux tables (inner join) | SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.x | table1.merge(table2, left_on = 'id', right_on = 'x') |
7 Statistiques descriptive
Pandas intègre de nombreuses méthodes permettant de calculer des statistiques agrégées telles que la somme, le nombre de valeurs uniques, le nombre de valeurs non manquantes, la moyenne, la variance, etc. Parmi ces outils, la méthode describe() est la plus générique, car elle fournit un résumé statistique complet des données. Elle fournit toutefois une grande quantité d’informations, ce qui peut parfois rendre leur lecture difficile. Il est donc souvent préférable de se concentrer sur certaines colonnes spécifiques ou de sélectionner les statistiques que l’on souhaite réellement analyser.
df.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
print("Somme :", df['Age'].sum(), "\n",
"Moyenne :", df['Age'].mean())
Somme : 21205.17 Moyenne : 29.69911764705882
Pandas nous permet de généraliser le calcul de statistiques à plusieurs colonnes :
df.loc[:, ['Age', 'Fare']].sum()
Age 21205.1700 Fare 28693.9493 dtype: float64
df.loc[:, ['Age', 'Fare']].mean()
Age 29.699118 Fare 32.204208 dtype: float64
Il est possible de généraliser ceci à toutes les colonnes en utilisant le paramètre numeric_only pour selectionner uniquement les variables pertinentes.
df.mean(numeric_only = True)
PassengerId 446.000000 Survived 0.383838 Pclass 2.308642 Age 29.699118 SibSp 0.523008 Parch 0.381594 Fare 32.204208 dtype: float64
8 Quelques visualisations rapides
Les tableaux numériques constituent sans doute une source précieuse d’informations pour comprendre la structure d’un jeu de données. Cependant, leur densité rend souvent leur interprétation difficile. Un simple graphique permet, d’un seul regard, de visualiser la distribution des données et d’évaluer le caractère plus ou moins normal d’une observation.
Pandas intègre des méthodes graphiques de base répondant à ce besoin. Elles s’avèrent très pratiques pour générer rapidement des visualisations, notamment après des manipulations complexes de données. Cette question sera abordée plus en détail dans la partie suivante Visualisation.
Il est possible d’appliquer directement la méthode plot() à une Series :
df['Age'].plot()

C’est exactement la même chose que :
import matplotlib.pyplot as plt
plt.plot(df.index, df['Age'])
plt.show()
Cette visualisation en series n’a pas vraiment de sens car l’age n’est pas une variable temporelle. C’est pour cela que l’on prefère souvent utiliser des histogrammes pour visualiser la distribution d’une variable quantitative.
df['Age'].plot(kind='hist') # ou df['Age'].hist()

Beacoup d’autres types de graphiques sont disponibles (boxplot, scatter, bar, pie, …).
9 Gestion des valeurs manquantes
La gestion des données manquantes est souvent un point délicat. De nombreuses stratégies ont été élaborées, les principales sont décrites dans une vignette. Nous ne décrirons ci-dessous que les plus élémentaires à mettre en oeuvre avec pandas.
Il est important de noter que le choix de la méthode de traitement des données manquantes peut introduire des biais dans l’analyse, et qu’il n’existe souvent pas de “bonne” solution universelle. Prenons un exemple concret : imaginons un jeu de données de santé provenant de plusieurs centres médicaux, dont un centre public (CHU) et cinq cliniques privées.Si, lors du prétraitement, vous décidez de supprimer toutes les observations comportant des valeurs manquantes, il se peut que les données issues du centre public soient entièrement éliminées. (Les dossier médicaux du secteur public utilise parfois des systèmes d’information plus anciens ou hétérogènes et ont souvent des contraintes administratives/de confidentialité plus strictes).
Cette suppression introduirait un biais d’échantillonnage, car vous ne conserveriez plus que la patientèle issue du secteur privé, généralement plus aisée que celle du secteur public. Or, le niveau de vie influence la probabilité de contracter certaines maladies. Ne pas tenir compte de cette dimension pourrait donc fausser vos conclusions et rendre vos résultats non représentatifs de la population dans son ensemble.
Comme dit précédemment il n’y a pas de bonne reponse, le plus important est de prendre en compte tous les biais que nous aurions pu introduire lors du préprocessing de nos données et de les notifier dans notre étude afin de fournir des analyses pertinent et “objective”.
Il est ainsi facile de supprimer toutes les observations présentant des données manquantes lorsque celles-ci sont peu nombreuses et majoritairement regroupées sur certaines lignes ou colonnes à l’aide de la méthode dropna.
Pandas permet également de faire le choix pour une variable qualitative de considérer np.nan comme une modalité spécifique ou d’ignorer l’observation correspondante.
Autres stratégies:
- Cas quantitatif: une valeur manquante est imputée par la moyenne ou la médiane. (on utilise la méthode
fillna). - Cas d’une série chronologique: imputation par la valeur précédente ou suivante ou par interpolation linéaire, polynomiale ou encore lissage spline.
- Cas qualitatif: modalité la plus fréquente ou répartition aléatoire selon les fréquences observées des modalités.
10 Exercices d’application
📝 Exercice 1
1. Importer le fichier dans un dataframe en utilisant la fonction
read_excel.2. Afficher les 5 premières lignes du dataframe.
3. Afficher un échantillon aléatoire de 10 lignes du dataframe.
4. Afficher les informations générales du dataframe. (methode
.info()) 5. Extraire le Nom, Catégorie, Origine et Prix des produits, pour :
- Catégorie = boissons
- Catégorie = boissons et prix >100
- Catégorie = boissons et origine=CEE et prix > 100
- Catégorie = boissons ou catégorie = condiments
- Catégorie = boissons et origine = CEE OU catégorie = condiment
- Catégorie = viande ET origine = CEE OU catégorie = condiment ET origine = extérieur
- prix > 70 et prix <=100
- Lister les aliments dont le prix est compris entre 100 et 200, et qui sont des «viandes»
- Lister les 15 produits les moins chers
6. Calculer la moyenne de prix des boissons distribuées à Lyon (
pivot_table)7. Quels sont les 5 produits les moins chers vendus à Lyon?
📝 Exercice 1
1. Importer le fichier dans un dataframe en utilisant la fonction
read_csv.2. Afficher les 5 premières lignes du dataframe.
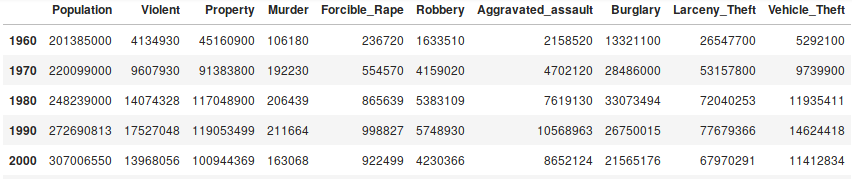
3. Créer le dataframe qui donne chaque indicateur pour chaque décennie. (
.resample())4. Quel était la décennie la plus dangereuse ?
5. Afficher l'évolution du nombre de meurtre par décennie.
Résultat attendu pour la question 3.